.svg)
.svg)
PRODUCTS

ReelShort-style apps publish more new episodes per week than most Netflix originals release in a year. Not an exaggeration. One short-drama app running 10 active series ships 50 to 200 episodes every seven days. Each one is 60-180 seconds of vertical video that needs multiple ABR renditions, thumbnails, subtitle tracks in 3-5 languages, DRM wrapping, and CDN delivery across 40+ countries.
The numbers behind this are worth sitting with. The global short-drama market has surpassed $8 billion (Media Partners Asia, 2026). In-app revenue hit $2.98 billion in 2025, up 115% year-over-year (Sensor Tower, 2025). Paid installs grew 155% globally (AppsFlyer, 2026). That growth rate doesn't describe a content trend. It describes an engineering problem. This isn't a content business with a video component. It's a video operations system that happens to ship dramas.
Most teams building these apps are still stitching together FFmpeg scripts, S3 buckets, and a prayer. The pipeline that worked at 10 episodes a week collapses at 100. Not because the tools are bad. Because the architecture was never designed for the operational pressure short-drama puts on every stage of the video pipeline.
Short-drama apps process 50-200 episodes per week, each requiring ABR encoding, thumbnails, subtitles, DRM, and analytics across dozens of markets. That's not a VOD workload. It's a continuous deployment pipeline for video. API-first automation replaces multi-service orchestration with single-call processing, webhook-driven catalog updates, and per-episode monitoring that catches failures before users do.
Key takeaways:
Do the math. A mid-sized app running 8 series with 15 new episodes each per week produces 120 episodes. Each needs 4 ABR renditions (240p, 480p, 720p, 1080p), a thumbnail sprite sheet, and 3 subtitle tracks. That's roughly 960 processing jobs every week. Add DRM packaging and you're past 1,000.
But job count only tells half the story. Short-drama video breaks standard VOD assumptions in three ways that matter for pipeline design.
First, the clips are short (60-180 seconds), so encoding overhead per file is proportionally higher. An FFmpeg job for a 90-second clip carries the same cold-start cost as a 45-minute episode. Second, every clip is vertical (9:16), which breaks default encoding presets optimized for 16:9. Third, the release cadence is relentless. No post-production buffer. Episodes go from final cut to live in hours, not weeks.
Then there's localization. A single episode bound for Southeast Asia, Latin America, and the US needs subtitle tracks in at least three languages, sometimes five. Subtitle files arrive late from translation vendors. Audio tracks occasionally have slight duration mismatches that cause sync drift. If your pipeline treats subtitles as a post-processing step bolted on after encoding, you will lose sync on a percentage of episodes and not notice until users report it.
Here's how the manual pipeline trap plays out: an engineer writes FFmpeg scripts that work for the first 20 episodes. Content scales to 80 a week. Subtitle tracks start dropping silently. Thumbnails generate at the wrong timestamp. A rendition ladder gets misconfigured and nobody notices for two weeks because there's no per-episode monitoring. The 1-star reviews in Seoul become the monitoring system.
Every episode crosses five stages between "uploaded" and "playing on someone's phone." These stages exist whether you build them yourself or use a managed API. The question is how much orchestration glue you want to own.

Ingest is where raw files enter the system: bulk imports from cloud storage or direct uploads from editing software. You need resumable uploads that survive spotty connections on 200MB files, and URL-based import for batch workflows where a producer drops 15 finished episodes into a folder. At 120 episodes per week, ingest is a queue management problem, not an upload problem.
Encode converts each episode into an ABR ladder optimized for mobile. Short vertical clips benefit from content-aware encoding, which analyzes scene complexity and allocates bitrate per scene rather than applying a fixed ladder. A locked-off dialogue scene needs far less bitrate than a chase sequence. On 90-second clips heavy on static shots and talking heads (most short-drama content), this meaningfully reduces file sizes. Exact savings depend on content mix, but the direction is consistent.
Enrich is where manual pipelines tend to break most visibly. This stage adds thumbnails at the right timestamp (not the first frame, which is usually black or a title card), subtitle tracks in multiple languages properly synced to audio, and intro/outro stitching for branding consistency. More moving parts than any other stage, and each one fails differently.
Deliver pushes the processed episode through a CDN with access control. Short-drama apps use a paywall model: first few episodes free, rest paid. That means signed URLs or DRM on a per-episode basis. Not per-series. Per-episode. If your access control is series-level, a user who buys episode 12 can access episode 50. Getting this granularity right requires token-based delivery with episode-level claims.
Monitor is the stage most teams skip and most regret skipping. Startup time, rebuffering, completion rate, playback failures: without per-episode QoE data, you have no visibility into whether episode 47 of a hit series is actually playing for viewers. A broken rendition tanks retention for the whole show. You won't know until users tell you.
The pipeline diagram above looks clean. Production is not. At scale, pipelines don't fail loudly. They fail silently, one episode at a time. Here's what actually goes wrong.
Failed encodes with no retry logic. An encoding job fails: corrupt source file, transient infrastructure error, unsupported codec. Without idempotent retry and exponential backoff, that episode silently disappears from the release queue. The content team thinks it shipped. It didn't. The fix is straightforward (retry with idempotency keys so you don't produce duplicate assets), but most hand-rolled pipelines skip it because it's invisible until it isn't.
Missing renditions. A 4-rung ABR ladder should produce 4 renditions. Sometimes one fails. The HLS manifest ships with 3, and nobody notices until a viewer on a slow 3G connection in Indonesia gets no playback at all because the lowest rendition doesn't exist. The only reliable catch is per-asset validation after processing completes: verify every expected rendition exists and is playable before marking the episode as ready.
Subtitle sync drift. Translation vendors deliver SRT files timed against a rough cut, not the final edit. If the final cut is trimmed by even 2 seconds at the top, every subtitle cue is 2 seconds late for the entire episode. Multiply by 120 episodes a week and 3 languages each. At this volume, catching drift requires automated sync validation that compares subtitle timing against actual audio duration, not human spot-checks.
Bad thumbnails. Auto-generated thumbnails often land on a transition frame, a black screen, or a blurred motion frame. For short-drama apps where the thumbnail grid is the primary browse interface, a bad thumbnail directly hurts episode tap-through rate. Some teams set a timestamp offset rule (generate at 30% of clip duration), but this is brittle across episodes with different pacing.
Webhook delivery failures. Your catalog service depends on a webhook to know when an episode is ready. If the webhook fails (endpoint temporarily down, returns a 500, times out), the episode sits encoded on the CDN but invisible in the app. Users see "Episode 47: Coming soon" for hours. The robust pattern: webhook retry with exponential backoff, a dead-letter queue for permanently failed deliveries, and a reconciliation job that periodically checks for processed-but-unpublished assets.
Region-specific playback issues. An episode plays perfectly in the US but fails in Japan because the CDN edge node serving Tokyo has a stale cache, or the DRM license server has higher latency in that region. Without per-region playback analytics, these issues are invisible to your US-based engineering team.
None of these are exotic. They're Tuesday. The difference between a reliable pipeline and a broken one isn't whether these happen. It's whether you find out before your users do.
The previous section described six failure modes. Every one of them is an orchestration problem, not a compute problem. The five pipeline stages don't disappear when you use a video API. What disappears is the glue between them: queue management, retry logic, validation checks, infrastructure maintenance.
Here's what a single episode looks like with FastPix's on-demand video API:
curl -X POST https://api.fastpix.io/v1/on-demand \
-u "$ACCESS_TOKEN_ID:$SECRET_KEY" \
-H "Content-Type: application/json" \
-d '{
"inputs": [{ "type": "video", "url": "https://storage.example.com/series-12/ep-47.mp4" }],
"metadata": {
"series": "midnight-contract",
"episode": "47",
"language": "en"
},
"mp4Support": "standard"
}
That call triggers ingest, adaptive bitrate encoding with content-aware optimization, thumbnail generation, and CDN delivery. When processing completes, a webhook fires with the playback ID and asset status. Your backend picks it up and updates the catalog. No polling. No queue management.
Notice the metadata field. For short-drama apps, episode-level metadata (series ID, episode number, language, release window) is the connective tissue between the video asset and every downstream system: your catalog, your paywall logic, your analytics. Attach it at ingest and every system that touches the episode can filter and route by it. This matters because, at 120 episodes a week, metadata inconsistency between your video store and your catalog is a class of bug that's hard to debug and easy to prevent.
For paywalls, signed URLs and DRM-ready outputs handle per-episode access control. Free episodes get public playback URLs. Paid episodes get JWT-signed URLs with episode-level claims that expire. Your payment system toggles access. The video infra enforces the token without knowing your billing logic.
For batch workflows, the batch migration tool ingests an entire folder of URLs in one operation. Each file processes independently and fires its own webhook on completion. Your catalog service handles episodes as they arrive, not as a batch.
Monitoring comes from FastPix Video Data: 50+ playback signals per viewer session, including per-episode startup time, rebuffering events, and completion rate. This is the layer that replaces the reactive pattern described in the previous section. Instead of discovering broken renditions through user complaints, you see them in a dashboard within minutes of first playback.
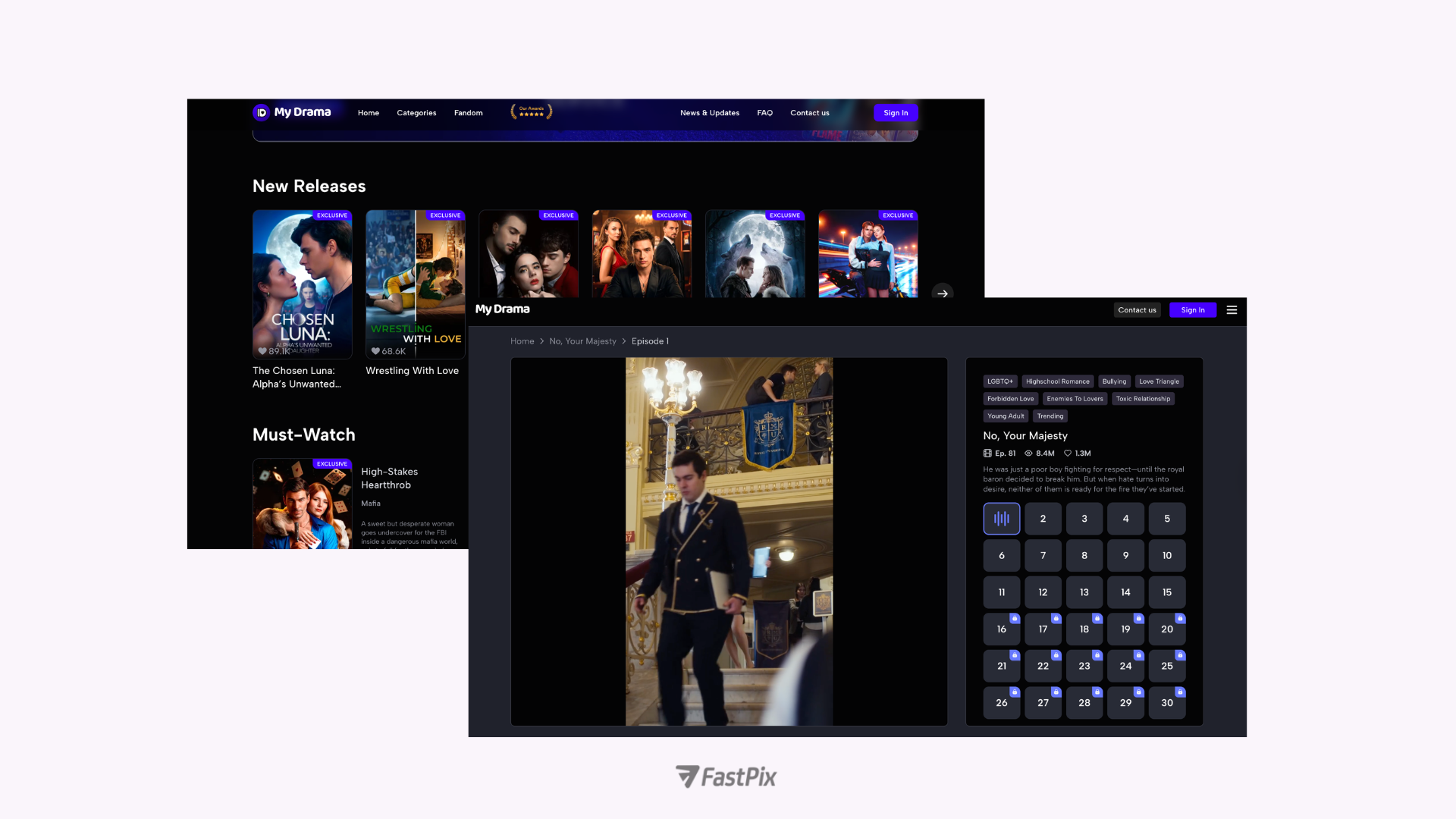
Holywater is a Ukrainian startup behind My Drama, one of the fastest-growing vertical drama apps outside China. Fox Entertainment took an equity stake in early 2026 (The Streaming Wars, 2026). Across four apps, the company reports over 55 million installs globally.
What do those numbers actually imply for the pipeline?
55 million installs across 40+ markets means CDN delivery from edge nodes on multiple continents, with per-region DRM license servers fast enough to not delay playback start. That maps directly to the "region-specific playback" failure mode above: Holywater's engineering team needs per-region monitoring, or a broken edge node in Jakarta takes down the experience for their entire Southeast Asian audience without anyone in Kyiv seeing it.
It means subtitle tracks in 5-8 languages per episode, each requiring QA. At the episode volume Holywater likely operates at, the subtitle sync drift problem from the previous section isn't an edge case. It's a daily operational risk that needs automated validation in the pipeline, not a manual review step.
Holywater reportedly uses AI across the production pipeline, from content ideation through post-production, treating each series like a software release cycle. But the less-discussed part is delivery infrastructure. At this scale, the content team can produce faster than a manual pipeline can process. That's the inversion point: when production velocity exceeds pipeline throughput, video infrastructure becomes the bottleneck for the entire business.
The lesson isn't "use AI for production." It's that content velocity without pipeline automation is just a backlog with better scripts. If you're building toward that scale, the tutorial on how to build a micro-drama app like ReelShort or DramaBox walks through the full architecture from ingest to playback.
Here's what most cost comparisons get wrong: they only compare compute. The compute costs between DIY and managed pipelines are usually close enough to argue either way. The engineering time is where the gap opens.
Below is a directional breakdown for a mid-sized app processing 120 episodes per week. These are approximate ranges, not exact quotes. AWS costs vary by region, reserved capacity, and configuration. FastPix costs are based on published pricing. The point isn't precision. It's which line items actually matter.
The compute line items are close. The real difference is the last row, and it's hard to quantify honestly because it depends on team size, existing tooling, and how many failure modes you've already solved. What we can say: every new series, every new language, every new target market adds operational surface area to a DIY pipeline. That surface area requires ongoing engineering attention. A managed API absorbs it.
Context-aware encoding compounds the difference over time. Short-drama content is heavy on dialogue and static shots, so per-title encoding reduces file sizes meaningfully compared to fixed bitrate ladders. Over a growing episode library, that means lower storage, lower delivery costs, and faster startup on mobile networks.
The short-drama market is projected to reach $7.99 billion globally in 2026 (360iResearch). The apps winning this market aren't the ones with the biggest production budgets. They're the ones shipping the most episodes with the least pipeline friction. That's an infrastructure decision, not a content decision.
The best way to evaluate a video pipeline is with your own files, not a sales call. FastPix gives you enough free credits to test encoding, delivery, and per-episode monitoring against real episodes before you commit to an architecture. Start now
Most short-drama apps generate 4-6 ABR renditions per episode: 240p, 360p, 480p, 720p, and 1080p, all vertical (9:16). The majority of playback happens on mobile. Content-aware encoding can drop this to 3-4 renditions at equivalent visual quality, because short clips with low scene complexity don't need every rung on the ladder.
Short-drama clips (60-180 seconds) carry higher per-file encoding overhead because each job has fixed startup costs regardless of duration. The 9:16 format requires different presets than 16:9. But release cadence is the real difference: 50-200 episodes weekly versus occasional releases in traditional VOD. Manual pipeline management doesn't survive that volume.
Short-drama apps typically offer the first 3-5 episodes free, then charge for the rest via coin purchase or subscription. This requires per-episode access control through signed URLs or DRM tokens. FastPix supports JWT-signed playback URLs where your payment backend controls episode access. The video infra enforces the token without knowing your billing logic.
Content-aware encoding (per-title encoding) analyzes each clip's visual complexity and allocates bitrate accordingly. Short-drama content is heavy on dialogue and static frames, so file sizes can drop meaningfully versus fixed ladders. The exact savings vary by content mix, but the direction is consistent: lower storage, lower CDN costs, faster mobile startup.
The most common failures are: encoding jobs that fail without retry logic (episodes silently disappear from the release queue), missing ABR renditions that break playback on slow networks, subtitle sync drift from translation vendors timing against rough cuts, webhook delivery failures that leave encoded episodes unpublished, and thumbnails landing on black frames. All of these fail silently. Catching them requires per-asset validation after processing and per-episode playback monitoring.
Yes. FastPix provides a batch migration tool that imports existing assets from URLs or cloud storage in bulk. Run the API in parallel with your FFmpeg setup, validate quality on a subset, and cut over gradually. The API accepts the same source files your scripts use. No re-encoding required unless you want to optimize older assets with content-aware encoding.
For a typical 90-second 1080p vertical clip, the full pipeline (upload, encoding, thumbnails, CDN distribution) typically completes in under a minute. Exact time varies by file size and complexity. Webhooks notify your backend the moment processing finishes, so catalog updates happen automatically. No polling.
FastPix provides 7 server SDKs (Node.js, Python, Go, Ruby, PHP, Java, C#) and player SDKs for Web, iOS, and Android. The server SDK handles episode ingestion; the player SDK handles playback with built-in analytics. Full docs at docs.fastpix.io/docs/sdks.










.avif)

.png)

