.svg)
.svg)
PRODUCTS

Most teams scaling video to a million users think they have a capacity problem. They imagine a slider labeled "users" and ask how far right to push it before the bill arrives.
The model is wrong. By 1M users, the bottleneck has moved at least four times. The layer that breaks at 100K is almost never the one that breaks at 1M. Video infrastructure fails in a predictable progression, and teams who scale well understand the order.
Video accounts for 82% of global internet traffic in 2026 (Servers.com, 2026). Getting the order wrong is no longer a research problem. It's the dominant line item on your bill.
Scaling video to 1M+ users is a sequence of architectural decisions, not one capacity upgrade. The encoding queue breaks first, then origin storage IOPS, then CDN cache hit rate, then player startup, then analytics ingestion. Each needs a different fix. Per-title and content-aware encoding beat fixed ladders at scale. Multi-CDN matters less than cache hit rate math. Aggregate QoE dashboards lie. Build-vs-buy inverts at 1M: in-house is cheaper at 10K, but the engineering cost to keep it alive at 1M usually exceeds the API bill of a managed platform.
Scaling implies a uniform stretch. Video infrastructure doesn't behave that way. One layer becomes the binding constraint, you fix it, and a different layer takes over. Your pipeline at 1M looks nothing like it did at 10K.
This catches most teams off guard. They optimize the encoder because it was the problem at 50K. At 200K, the CDN cache becomes the problem and the encoder work stops mattering. At 800K, player startup on cold caches breaks and nobody has touched the player in eight months.
Teams who scale well aren't the ones with the best individual components. They're the ones who predict which one is about to break and start working on it three months early.
Use this as a checklist. If you can't name your current binding constraint, that's where to look.
The third row is the interesting one. At 1M users, the bottleneck is almost always cache hit rate, and almost nobody designs for it explicitly. They design for "more bandwidth," then watch the CDN bill triple because every miss touches origin.

Most pipelines use a fixed adaptive bitrate ladder. Six renditions, fixed bitrates, every asset gets the same treatment. It works until it doesn't.
A fixed ladder gives the same bitrate budget to a still-frame talking head and a high-motion sports clip. The talking head wastes bits. The sports clip drops quality. At 10K you don't notice. At 1M, your CDN egress is paying for wasted bits on every delivery.
At 1M users, the encoding cost from per-title or content-aware is almost always cheaper than the egress savings. The math isn't close on a large catalog. Most teams don't switch because rebuilding the encoder feels expensive and the egress bill arrives at a different cost center.
70% of organizations plan to expand AI/ML in their encoding workflows in 2026 (NETINT state of video encoding survey via StreamingMediaBlog.com, March 2026). That's not hype. That's encoding teams catching up to the math.
The most important number in your video stack is the percentage of requests served from the edge without touching origin. Everything else is derived. Egress, origin load, tail latency. All of it is a function of cache hit rate.
Here's the request path when it works:
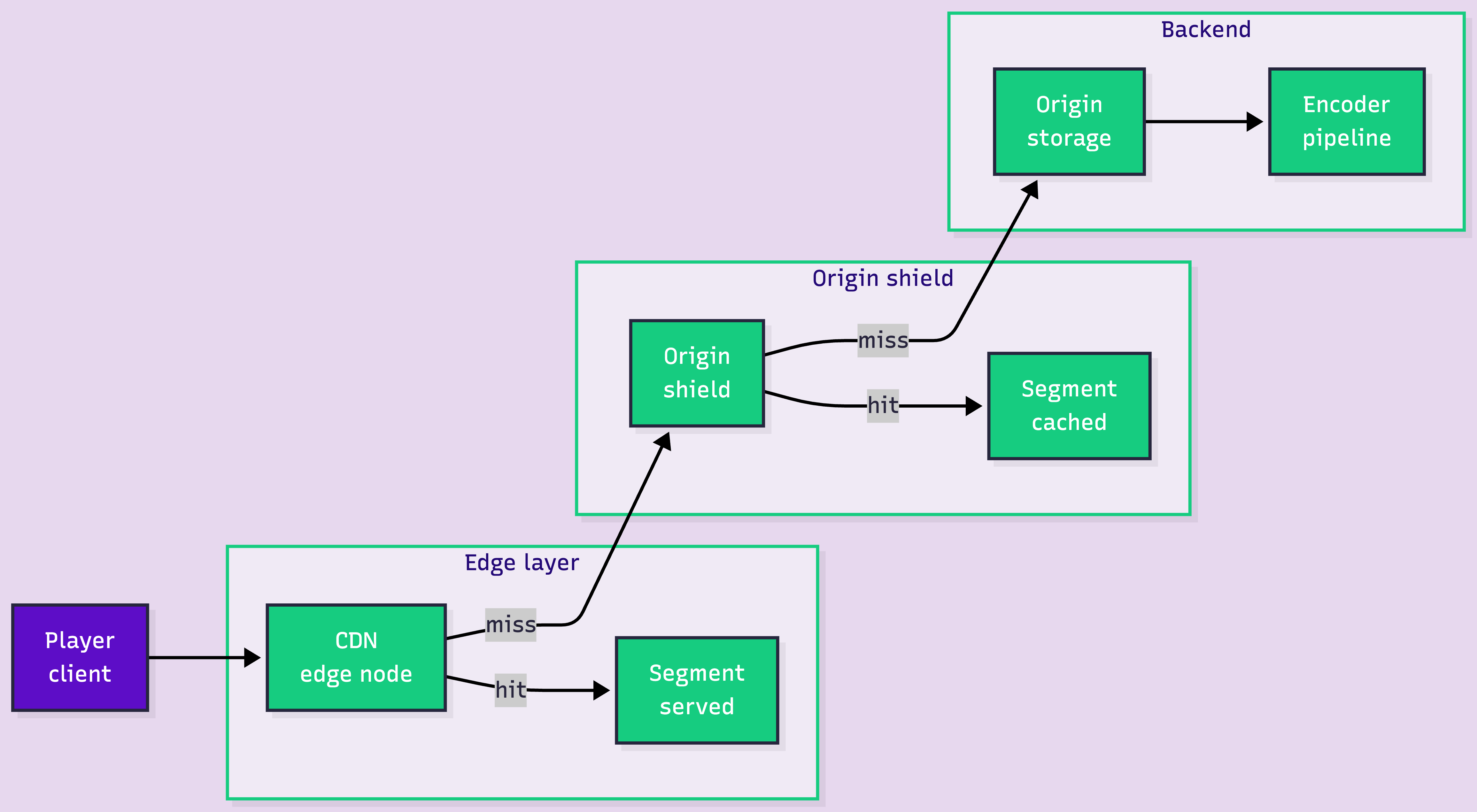
The math is brutal. At 1M concurrent viewers pulling 2-second segments, you're serving roughly 500,000 segment requests per second. A 95% hit rate means 25,000 requests per second hit your origin shield. 90% means 50,000. 85% means 75,000. The gap between 95% and 85% is the difference between a healthy origin and a smoking crater.
This is why multi-CDN usually solves the wrong problem at 1M users. Multi-CDN gives you failover. It does not improve cache hit rate. If your cache key includes a session token or per-user query parameter, your hit rate is destroyed before the request leaves the player. Fix the cache key first.
The first dashboard you build shows averages. Average startup, average rebuffer, average bitrate. Comforting, and useless for diagnosing what's broken at scale.
Averages lie because video QoE has a brutal long tail. 95% of sessions can be perfect, and the broken 5% generate the support tickets, the churn, and the CFO emails. Averages don't see them. p95 doesn't always either. You need per-session telemetry, sliced by device, network, region, content type, and player version.
Treat observability as a first-class layer, not a dashboard you bolt on after launch. Retrofitting session telemetry at 1M users means rewriting the player and the ingest pipeline simultaneously.
Up to about 100K users, building your own is usually cheaper. One or two content patterns, simple CDN setup, encoder doesn't need much tuning. Maintenance is low because the system is simple.
At 1M, the math inverts. You need encoding queue management, multi-region storage tiering, CDN routing, per-session telemetry, a player SDK that handles ABR across devices, and a control plane that survives regional outages. Each is a small team's worth of engineering. Add it up and the in-house cost usually exceeds the API bill of a managed platform by 2-3x.
For a step-by-step walkthrough on setting up each layer, here's the implementation guide.
We built FastPix because we kept watching teams burn quarters on the same problems: encoder queue tuning, cache key normalization, cold-cache startup, telemetry drops. None of it is differentiating work. It's the cost of running the pipeline.
FastPix is a single video API for encoding, ingest, delivery, playback analytics, and a player. The argument isn't magic. The argument is that it removes the layers most teams underestimate, so your engineers can ship the product.
Try FastPix on $25 free credits. No credit card. Qualifying startups can stack $600 in additional startup program credits on top.
Buying doesn't always win. At 1M users there's a real category of teams who should build.
If video is the product, not a feature, you probably want to own the pipeline. Companies that scale video into the tens of millions almost all run custom encoders, players, and CDN integrations. At that scale, a 10% gain in egress efficiency or 200ms in startup is worth a dedicated team.
If you're a video product company under 1M users, that calculus is almost never positive yet. Buy the pipeline, ship the features, revisit the build question when video efficiency becomes a line item your CFO mentions by name.
Scaling video to a million users isn't a problem you solve with a bigger box. You solve it by knowing which layer is about to break next. The teams who get this right treat the bottleneck progression as a roadmap, design observability in before they need it, and run the cache hit math before signing a CDN contract.
The hard part at 1M users isn't capacity. It's discipline. The decisions you make at 50K determine whether 1M is a milestone or a meltdown.
FastPix replaces 10+ AWS video services with one API. Playback analytics free up to 100K views per month. $25 free credits on signup.
Get your API key. No credit card required. Qualifying startups stack $600 in additional credits through the FastPix Startup Program. YC and VC-funded teams get an additional $1,200 on top.
The encoding queue breaks first around 10K users, then origin storage IOPS at 100K, then CDN cache hit rate at 1M, then player startup and analytics ingestion at 10M. Each tier needs a different fix. The common mistake is over-investing in the layer that just broke instead of the one coming next.
Multi-CDN gives failover and geographic coverage. It does not improve cache hit rate, which is the dominant cost driver at 1M users. Fix cache key normalization and rendition strategy first. Add a second CDN for redundancy after.
The cost depends on cache hit rate and encoding efficiency, not the headline price per minute. A pipeline with a 95% hit rate and per-title encoding can cost a fraction of one with 85% and a fixed ladder, on the same platform. Run the math on egress at your actual hit rate before comparing vendor pricing.
Per-title generates a bitrate ladder per asset by complexity. Content-aware allocates bits per scene by visual complexity. At 1M users on a large catalog, content-aware almost always wins on total cost. The reason most teams don't adopt it is engineering inertia, not bad math.
The inflection is between 100K and 500K users, depending on product complexity. Below that, the pipeline is simple and maintenance is low. Above that, the layers you have to keep alive start eating engineering capacity. If your video team spends more than 20% on non-differentiating infrastructure work, the build calculus has already flipped.
Per-session startup time, rebuffer ratio, and video start failure rate. Reported as p95 and p99, not means. Sliced by device, network, region, content type, and player version. If your dashboard only shows averages, you're blind to the tail that generates churn.










.avif)

.png)

